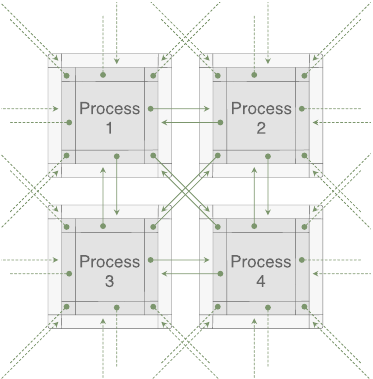
Multi-GPU: Distribution of local lattices on the individual GPUs
To work with multiple devices, SIMULATeQCD splits a lattice into multiple sublattices, with partitioning possible along any of the four Euclidean space-time directions. Each sublattice is given to a single GPU. In addition to holding a field restricted to that sublattice, which we call the bulk, the GPU holds a copy of that field from the borders of the neighboring sublattices–we call these copies the halo. A schematic drawing of the exchange of halos between different GPUs is shown below.
If we consider a lattice of size Nx*Ny*Nz*Nt, each GPU has a local Lattice of size
(Nx_sub+2*Halo_depth) *(Ny_sub+2*Halo_depth) * (Nz_sub+2*Halo_depth) * (Nt_sub+2*Halo_depth),
where N_sub = N/Cores_i with i=x,y,z,t.
For example if we have a lattice of size \(32^3\times 8\) and we split the lattice in x direction with
halo_depth=1, both GPU’s will have a local lattice size of \(18\times 34\times 34\times 10\).
This can be accomplished with:
const int LatDim[] = {32, 32, 32, 8};
const int NodeDim[] = {2, 1, 1, 1};
When using P2P, for a lattice with size e.g. \(120^3 \times 30\), it is best (=lowest overall memory consumption) to split the lattice like this:
1 GPU: 1 1 1 1, Size per GPU: 28476.5625 MiB
2 GPUs: 2 1 1 1 or 1 2 1 1 or 1 1 2 1, Size per GPU: 18509.765625 MiB
4 GPUs: 4 1 1 1 or 1 4 1 1 or 1 1 4 1, Size per GPU: 11390.625 MiB
8 GPUs: 1 2 4 1 or 1 4 2 1 or 2 1 4 1 or 2 4 1 1 or 4 1 2 1 or 4 2 1 1, Size per GPU: 6976.7578125 MiB